On se dit qu’on a vraiment raté notre coupe quand le mouvement des gilets jaunes s’est éclaté, parce que notre sujet au début, c’était le mot « jaune ». La raison pour laquelle on a abandonné ce sujet, c’est le défaut de ressource web. Du coup, on s’orientait vers « traduction automatique » afin de construire un corpus comparable à partir des sites d’internet en trois langues. On ne doute pas le résultat ne soit sans surprise, c’est-à-dire, le résultat final ne pourra pas nous révéler quelque chose de contraire à notre presupposition.
Avant d’aborder le sujet final, nous allons voir un peu de statistique:
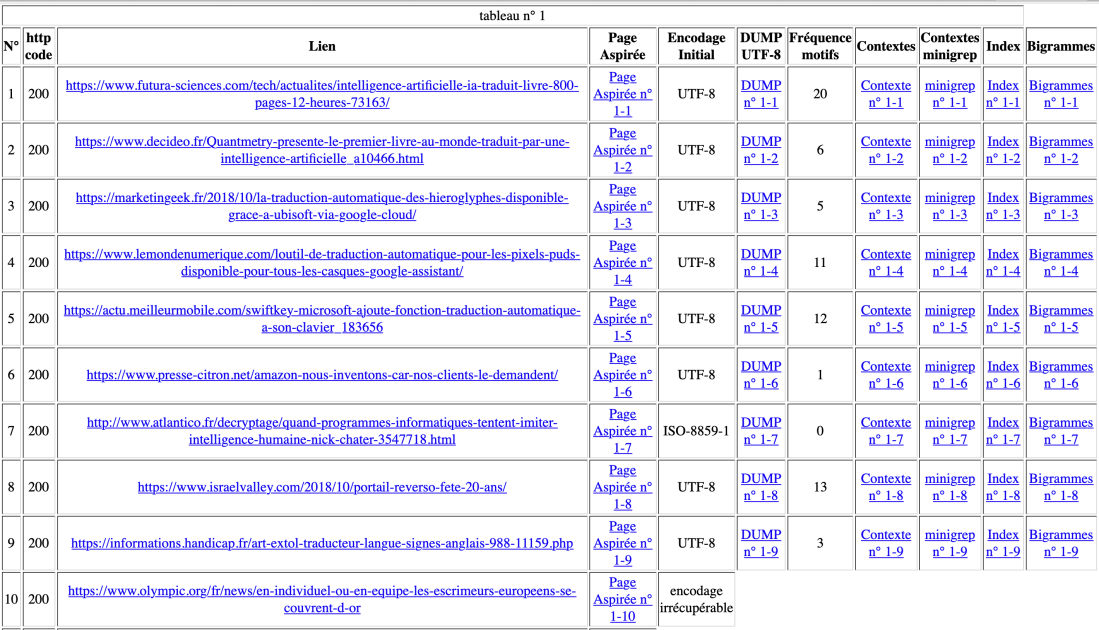
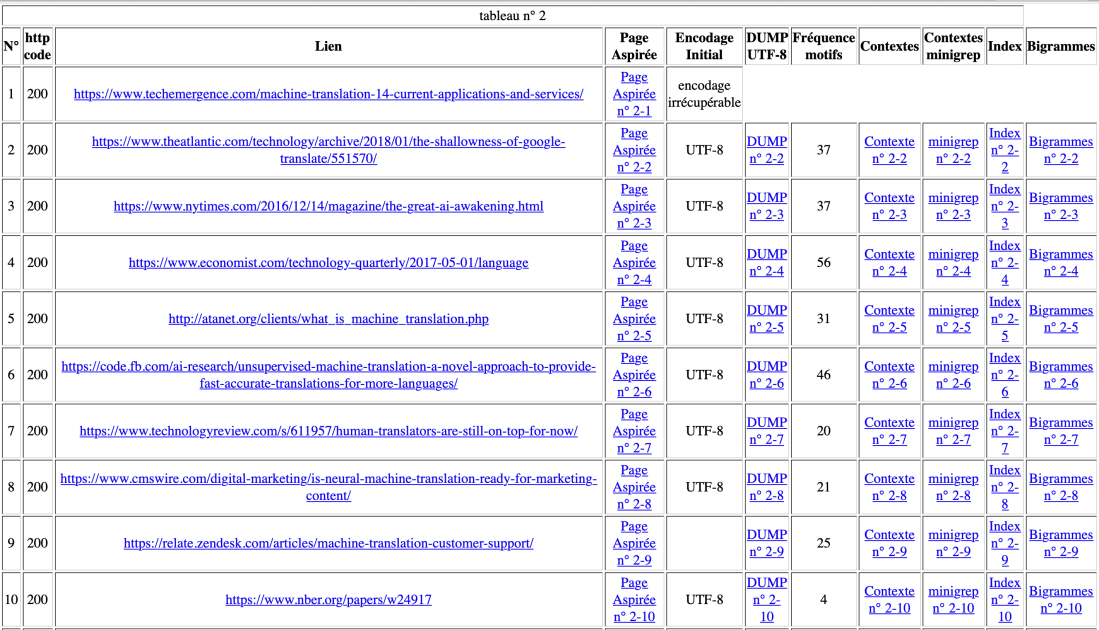
Français, 55 urls, 4 http code autres que 200, et 6 « encodage irrécupérable », 10 « fréquence motif 0 »;
Anglais, 59 urls, 9 http code autres que 200, et 7 « encodage irrécupérable », 18 « fréquence motif 0 »;
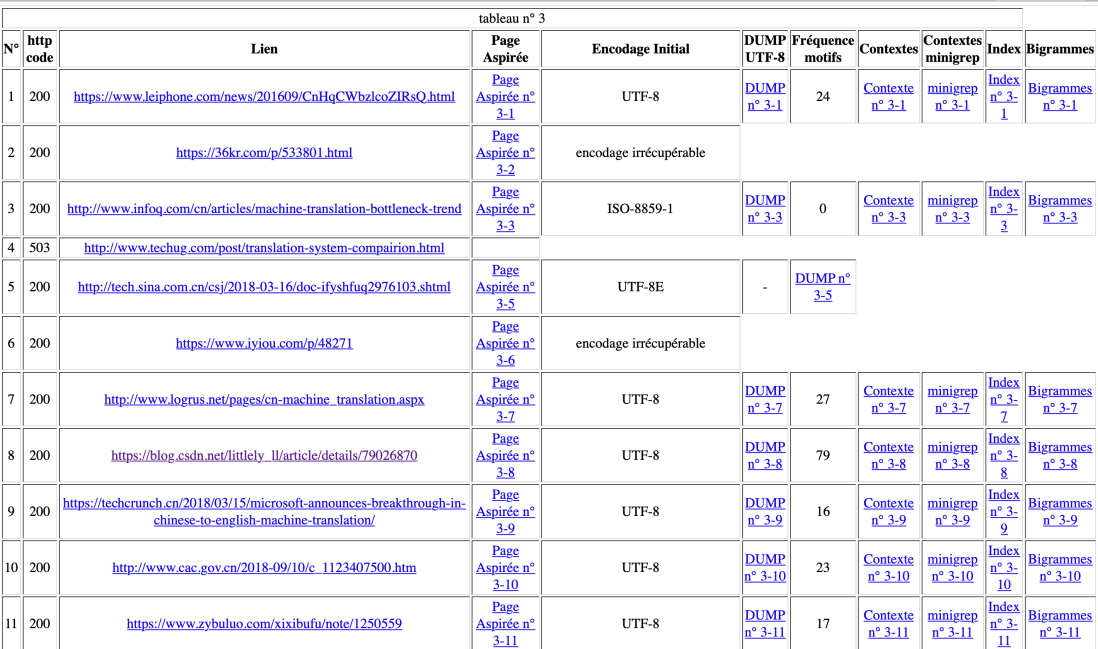
Chinois, 59 urls, 3 http code autres que 200, et 20 « encodage irrécupérable », 21 « fréquence motif 0 »;
La fréquence du motif est assez inattendu: il y a forcément une erreur. Soit, les sites que nous avons trouvés au début du cours ont été supprimés (c’est 2019 maintenant); soit, on peut contribuer au script de minigrep en perl, en particulier dans la rédaction de motif, c’est-à-dire, au lieu d’écrire ‘machine translation|traduction automatique|机器翻译’, le résultat sera différent si on écrit ainsi ‘machine|translation|traduction|automatique|机器|翻译’.
Ensuite, nous allons voir les cooccurrents des motifs.
Commençons par le français:
La fréquence de « traduction » (376) est plus que double de celle de « automatique » (131).
La cooccurrence de « traduction » et « automatique » est 131, donc, on peut dire que « traduction automatique » forme un mot, et les cooccurrents de « automatique » peuvent considérés faisant partie de « traduction automatique ».
Les cooccurrents du mot « T|traduction automatique» sont: neuronale(22), Systran(21), Google(15), outil(11), application(7), intelligence(7), Focus(5);
En anglais:
La fréquence de « traduction » (613), la fréquence de « machine » (280).
Pareillement, les cooccurrents de « machine translation » sont: market(41), neural(47), technology(19), statistical(18).
En chinois:
La fréquence de « machine » est 1032, « traduction » 1331.
Les cooccurrents de « 机器翻译 » sont : 神经Neurone(181), système系统(113), 网络réseau(100), 学习apprentissage(99), 人工artificiel(168),统计statistique(66).
Pour que ce soit plus clair, nous avons fait un tableau avec les 4 cooccurrents les plus fréquents, et un ajout sur la fréquence de Google dans le corpus.
| Langues | Anglais | Chinois | Français |
| market(41) | 神经Neurone(181) | neuronale(22) | |
| neural(47) | 系统système(113) | Systran(21) | |
| technology(19) | 网络réseau(110) | Google(15) | |
| statistical(18) | 学习apprentissage(99) | outil(11) | |
| Fréquence de GOOGLE | Google(42) | 谷歌Google(68) | Google(33) |
En conclusion:
1, Quand on parle de la traduction automatique sur la presse, c’est souvent la traduction automatique aux réseaux neurones;
2, Google n’est pas forcément le coocurrents de traduction automatique, mais c’est aussi très fréquent dans le corpus. Et il est surprenant de constater Systran dans le corpus de français.
Amélioration sur le script:
L’idée de départ était de voir l’attitude de la presse envers la traduction automatique, sceptique, ou unanimement favorable. Il faut donc réfléchir sur la construction de méthode, en particulier la recherche de motif, pour mettre vraiment l’accent sur l’émotion, ou l’attitude de l’article.